From Query to Output: The process of how chatbots work
Introduction
What if I told you that AI is older than the World Wide Web? It’s hard to fathom since today, these tools are almost like conjuring magic, but it’s true. Ever since the first computers, it’s been the driving force behind innovation in computing and really came about when Alan Turing in 1950, posed the critical question, Can machines think? famously known as “The Turing Test”. Many scholars today credit these “thinking machines”, modern AI, for the inception of the 4th industrial revolution; others say that it’s our direct connection to the “voice of God”. Regardless of one’s take, we cannot deny it’s impact on our society, but more importantly, how critical it is for us to understand how these tools work. In this piece, I will attempt to dissect the process of the most widespread application of AI: the chatbot.
Figure 1.1 A model of what happens under the hood when we converse with a chatbot
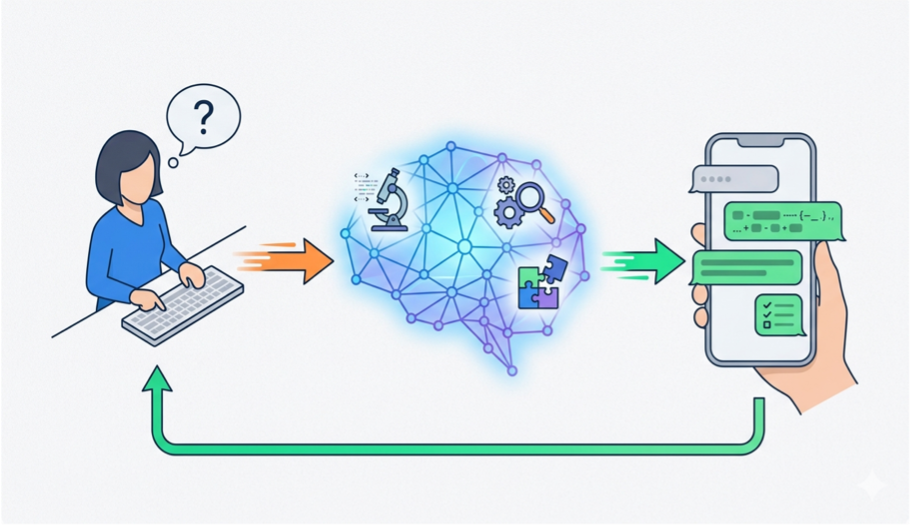
Chatbots are the conversational interface by which we interact with artificial intelligence. As mentioned, it has become the most popular application of AI and is very useful in many domains, from reasoning to basic fact retrieval. Because of the massive amounts of compute required for them to work, most chatbots are hosted on cloud-based servers that are stored in huge data centers. To average users, the process of chatbots is a “blackbox” where the inner workings are hidden, however, the general process of how they work can be broken down into 3 main components:
1. Natural language processing (Tokenization)
2. Neural network processing (The Math)
3.Generation (Decoding)
Phase 1: Tokenization
Before a chatbot can reason about what an input is, it must first convert our raw text/speech into a form that machines understand: Numbers. This is the domain of Natural Language Processing (NLP), the subfield of AI that enables machines to understand and generate human language. The first essential building block is tokenization which is breaking a piece of text (a sentence or document), or sound bite (human voice recording), into smaller, meaningful units called tokens. We can think of tokens as the bricks that build the house of language, from a machine’s perspective. For example, a sentence like:
“I need help with my order”
doesn’t go into the model as a whole. Rather, it’s broken into individual units like:
{I} {need} {help} {with} {my} {order}
for further processing.
Figure 1.2 Illustrating a sound bite and text-based artifacts being converted into tokens (represented as nodes in the graph)
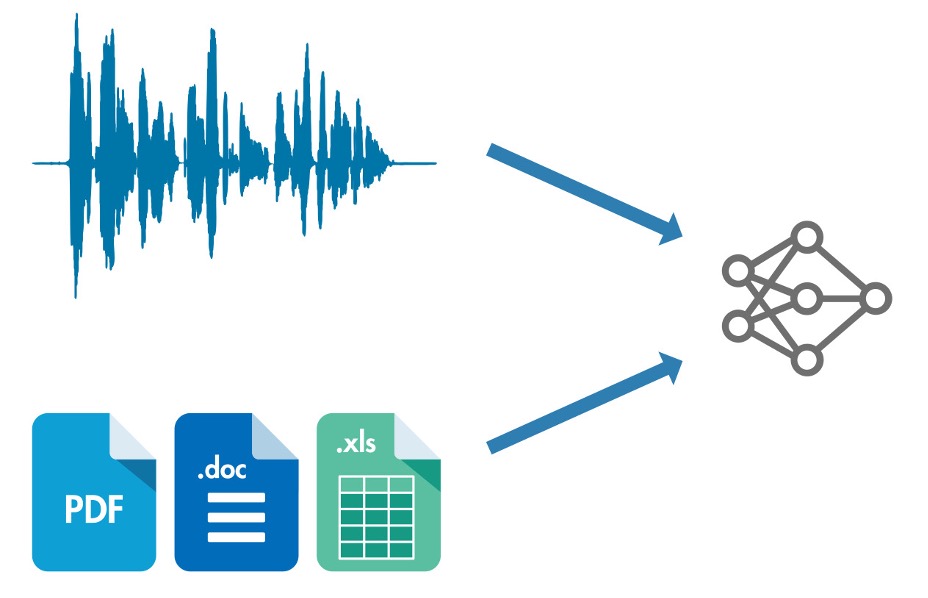
To prepare the tokens to be processed the next step would be embedding. Here, each token is mapped to a numerical vector (basically a list of numbers) that the model can understand and process. These vectors place words in an abstract, high dimensional space, where similar words like {king} and {queen} are mathematically related.
Phase 2: Neural Nets
Once the input has been tokenized and embedded (converted into numbers), the actual “thinking” happens inside a neural network known as the Transformer. We can think of a neural network as a very sophisticated pattern matching machine.
Figure 1.3 Graphical representation of a neural network where the nodes: pink = tokens in high dimensional space (3), arrows = calculations, yellow = matching words (4)
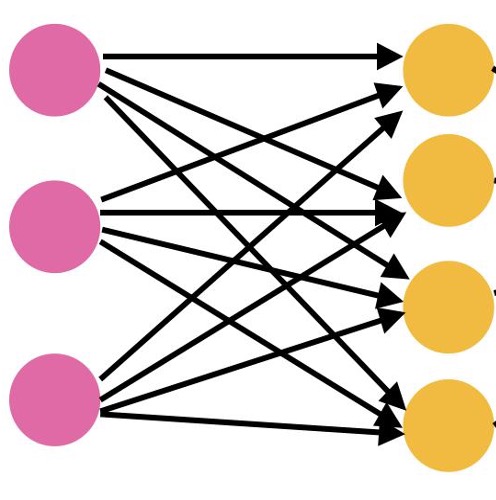
Transformers are trained by reading enormous amounts of human written text (books, websites, conversations) and gradually learning the statistical relationships between words and ideas. After enough exposure, it develops an intuition for things like what kinds of words tend to follow other words or what a question looks like. When a message (input) arrives, the network doesn’t look up an answer in a database or follow a script. Instead, it processes the input through many layers of mathematical operations, each layer refining the representation of the message a little further, until it arrives at a rich internal understanding of what you’re asking and what kind of response would make sense.
TL;DR: Neural networks provide the backbone for “human like” language modeling by recognizing patterns in massive datasets and powering Large Language Models (LLM’s).
Phase 3: Generation
Once the transformer has processed the input through its attention layers, it produces an output which is referred to as Decoding . At each step during the decoding phase, the model doesn’t simply output the next word, rather, it outputs a probability distribution over its entire vocabulary. For example, the word {sunny} might have a 40% probability, {rainy} a 25% probability and {cold} a 15% probability, and so on. GPT style models use masked self-attention during generation. They pay attention to all tokens from the prompt up to the last word predicted, and based on that growing input, predict the next work in the sequence.
Figure 1.4 Graphical representation of generated output (blue) from attention layer in transformer (yellow)
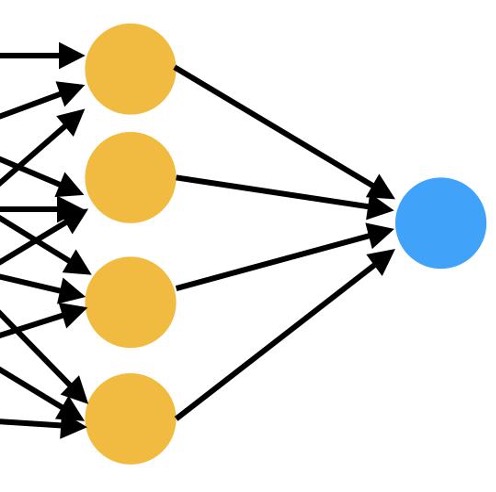
The result of this iterative process is a response generated one word at a time, yet coherent enough to feel like a natural and fluid reply. This step closes the conversational loop outputting the sycophantic undertone that we’re grown accustomed to…
“Hey [insert name], I’d love to help you with your order!”
Conclusion
In conclusion, when we think about the broader social context and AI, understanding the language surrounding and use of LLM’s should be at the top of everyone’s mind. Shifting our mindset from viewing chatbots as “convenience” tools to infrastructure driving education, healthcare and software development, just to name a few, can be very beneficial for a society. When users understand that chatbots are just highly complex statistical calculators rather than “thinking” genies, it takes us one step closer to a more realistic and critical approach to AI literacy.
Work Cited
MathWorks. “Natural Language Processing (NLP).” MathWorks, figure 1.2 http://www.mathworks.com/discovery/natural-language-processing.html
Specbee. Specbee, www.specbee.com figure 1.3/1.4
Nano Banana. Fig. 1.1. 2026, Generated image.